Dynamic Tables in Snowflake are a powerful feature introduced to streamline data pipeline development. They allow users to define declarative data transformations that stay up-to-date automatically, without having to manually orchestrate complex scheduling or dependency management.
Key Features
1.Declarative Transformation Logic Define the transformation using SQL once, and Snowflake handles the execution and refresh logic behind the scenes.
2.Automatic Data Freshness You can set a target lag (e.g., 30 minutes), and Snowflake ensures that the data in the dynamic table is no more than that old.
3.Incremental Processing (optional) Dynamic tables optimize performance by only processing new or changed data since the last refresh, reducing compute costs and latency.
4.Failure Recovery and Monitoring Snowflake automatically handles failures and retries. It also provides metadata to track refresh history, lag, and job details.
Architecture
The diagram below demonstrates how you can construct multi-stage, resilient data pipelines using Snowflake’s dynamic tables, with automatic refresh propagation and clear separation of data stages (source → raw → cleaned → enriched).
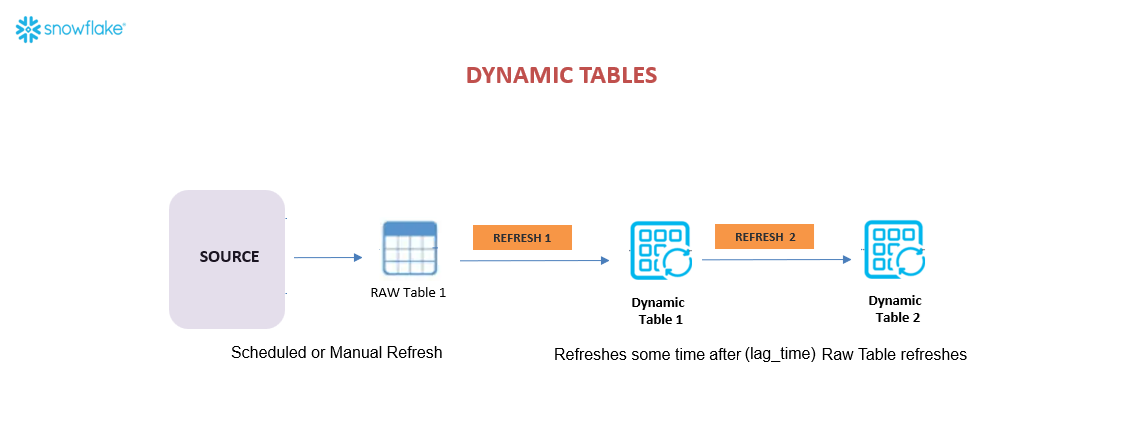
The detailed steps are listed below:
SOURCE Data originates from an external source—this could be logs, APIs, files, etc. This source is manually or on a schedule ingested into the system.
RAW Table 1 The raw ingested data is stored in a standard table (RAW Table 1). This table is not automatically updated—it depends on external triggers or processes, such as a cron job.
Dynamic Table 1 Once RAW Table 1 is refreshed, Dynamic Table 1 gets updated. The update does not happen immediately—it respects a user-defined TARGET_LAG time, meaning it will refresh shortly after the source data changes. This table applies SQL logic to transform or clean the raw data.
Dynamic Table 2 Following the update of Dynamic Table 1, Dynamic Table 2 gets refreshed in a similar fashion. Again, this table may have its own TARGET_LAG setting and transformation logic based on the first dynamic table.
Some tips to consider while building this pipeline:
- Ensure Chained Dependency: Each step depends on the refresh of the previous one.
- Target Lag Awareness: Dynamic Tables don’t refresh in real time, but within a tolerable freshness window.
- Declarative Pipeline: The entire flow can be built using SQL with minimal orchestration overhead.